RAG as a Tool Is the Only Right RAG
Why traditional RAG pipelines are wasteful. RAG as a tool call lets the LLM decide when and what to retrieve — better results, cleaner architecture.

When we built AskMGM, our civic AI platform for Montgomery, we tried traditional RAG first. It was wasteful. Here's the approach that actually worked.
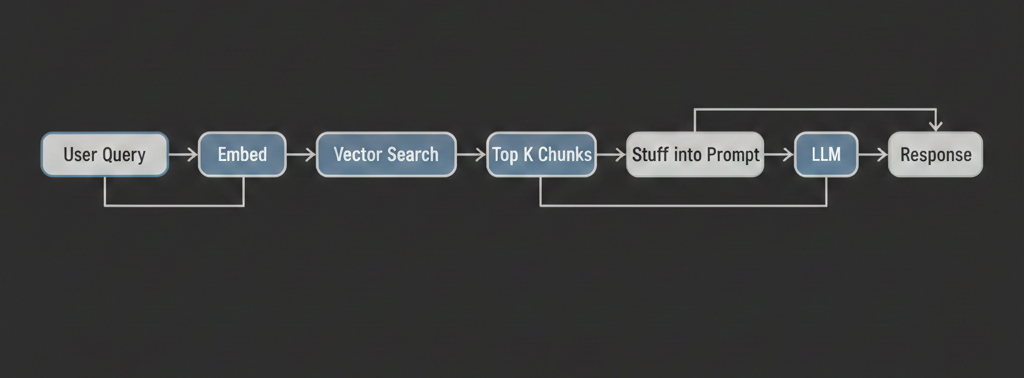
Here's the standard RAG architecture that every tutorial teaches you: user asks a question, you embed the question, search a vector database, grab the top-k chunks, stuff them into the LLM's context window, and generate a response. Retrieve then generate. RAG. (If you want the full playbook on making that pipeline production-grade, see our 7 production RAG patterns guide.)
It works. Kind of. And it's also one of the worst ways to build a production AI system.
The problem isn't retrieval-augmented generation as a concept. The concept is great — ground LLM responses in real data so they don't hallucinate. The problem is the pipeline. The rigid, linear, "retrieve on every single query no matter what" pipeline. The LLM has zero say in whether retrieval happens, what gets searched for, or whether the results are any good. It just receives a pile of chunks and does its best.
There's a better way. Give the LLM a retrieval tool and let it decide when to use it.
The Traditional RAG Pipeline Is Dumber Than You Think
Let's walk through what actually happens in a standard RAG setup when a user types "hi, how are you?"
- The message gets embedded into a vector.
- That vector hits your vector database.
- The database returns the top 5 most "semantically similar" chunks.
- Those chunks — which have nothing to do with a greeting — get injected into the system prompt.
- The LLM generates a response while ignoring the irrelevant context.
You just burned vector DB compute, embedding API calls, and extra input tokens on a greeting. Multiply this by every casual message, every follow-up question, every "thanks" and "got it" in a conversation. It adds up.
But wasted compute is the minor problem. The bigger issues are architectural.
The User's Query Is Usually a Bad Search Query
When a user types "why isn't this working with the enterprise plan?", that's a conversational question directed at an assistant. It's a terrible vector search query. What should you actually search for? "Enterprise plan limitations"? "Enterprise plan troubleshooting"? "Feature comparison between plans"?
In a traditional RAG pipeline, you don't get to make that decision. The raw user message becomes the search query. Some teams bolt on a query rewriting step — an extra LLM call to reformulate the question before searching. That helps, but now you've added latency and complexity to a pipeline that still fires on every single message regardless of whether retrieval is needed.
One Shot, No Iteration
Traditional RAG gives you one chance. You search, you get chunks, you generate. If the chunks are wrong — bad relevance, missing the actual answer, pulled from the wrong document — tough luck. The LLM has no mechanism to say "these results aren't useful, let me try a different query."
A human researcher doesn't work this way. They search, scan the results, adjust their query, search again, maybe look in a completely different source. Traditional RAG doesn't allow any of that. It's a single rigid pass.
Context Window Pollution
Every chunk you stuff into the context window is competing for the model's attention. Irrelevant chunks don't just waste tokens — they can actively confuse the model. There's well-documented research showing that LLMs perform worse when relevant information is buried in a sea of irrelevant context. You're paying more money for worse answers.
RAG as a Tool: Let the LLM Drive
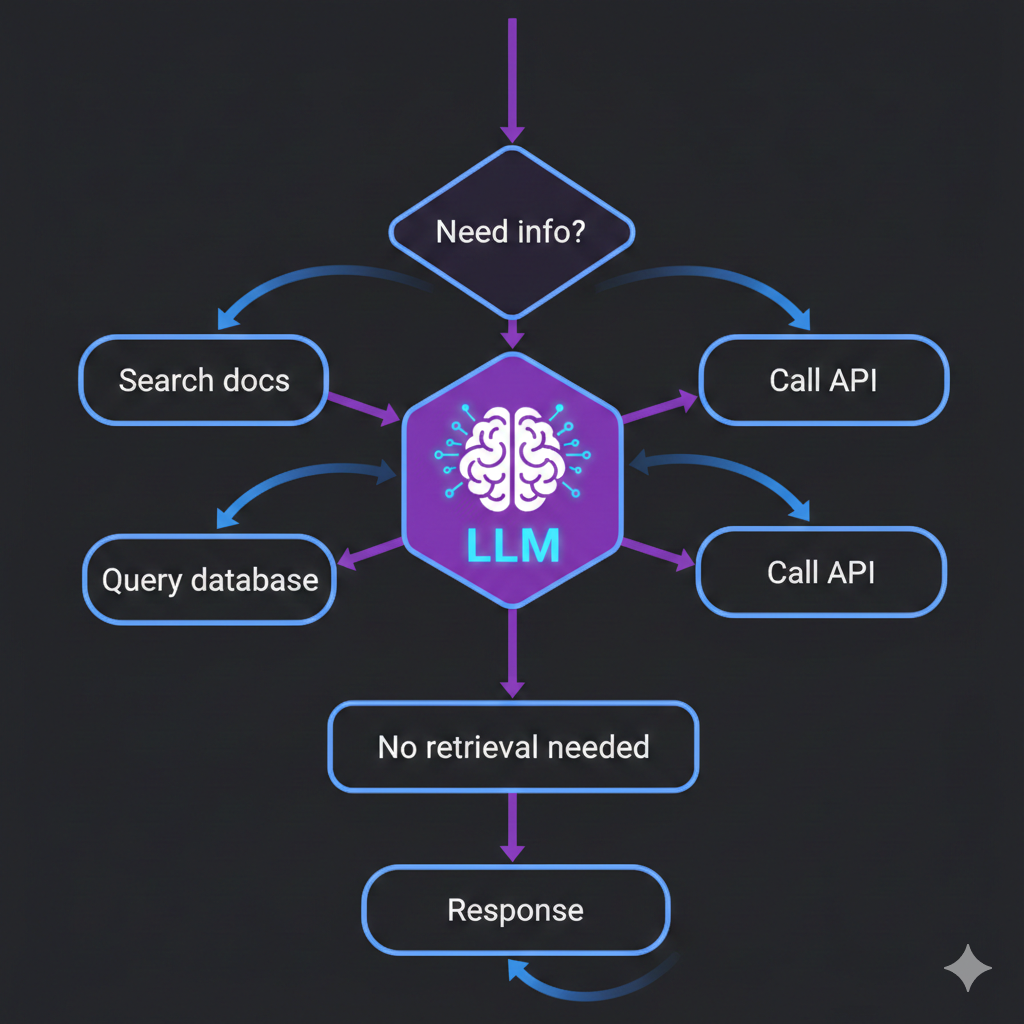
The fix is simple in concept: instead of building retrieval into the pipeline, expose retrieval as a tool the LLM can call.
Modern LLMs support tool calling (also called function calling). You define a set of tools — functions with names, descriptions, and parameters — and the model decides when to invoke them. The model generates a structured tool call, your system executes the function, returns the results, and the model continues generating its response.
Retrieval is just another tool. Search the knowledge base, query the database, look up a document. The LLM calls it when it needs it.
Here's what changes:
The LLM decides WHEN to retrieve. User says "hi"? No tool call. User asks about pricing? The model calls the search tool. This alone eliminates a huge amount of wasted computation.
The LLM formulates the search query. Instead of embedding the raw user message, the model writes an optimized search query. It understands what information it actually needs and can phrase the query to maximize relevance.
The LLM can search multiple times. First search didn't return what it needed? It can try again with a different query. It can search one knowledge base, then another. It can narrow down from a broad query to a specific one. This iterative retrieval is impossible in a traditional pipeline.
Retrieval composes with other tools. In a real assistant, the LLM might need to check a database, call an API, and search documentation — all in the same turn. With tool-based RAG, retrieval is just one capability alongside others. Traditional RAG treats retrieval as a special architectural layer. Tool-based RAG treats it as what it is: one of many things the assistant might need to do.
What This Looks Like in Code
Here's a simplified tool definition for a retrieval function:
const retrievalTool = {
name: "search_knowledge_base",
description:
"Search the company knowledge base for information about products, " +
"policies, pricing, and technical documentation. Use this when the " +
"user asks a question that requires specific company information.",
parameters: {
type: "object",
properties: {
query: {
type: "string",
description:
"A clear, specific search query. Reformulate the user's " +
"question into an effective search query.",
},
category: {
type: "string",
enum: ["products", "policies", "technical", "pricing"],
description: "Optional category to narrow the search scope.",
},
},
required: ["query"],
},
}
And the handler that executes when the LLM calls it:
async function handleSearchKnowledgeBase(args: { query: string; category?: string }) {
// Embed the LLM-formulated query — not the raw user message
const embedding = await embedQuery(args.query)
// Search with optional category filter
const results = await vectorDB.search({
vector: embedding,
topK: 5,
filter: args.category ? { category: args.category } : undefined,
})
// Return results to the LLM for it to synthesize
return results.map((r) => ({
content: r.text,
source: r.metadata.source,
score: r.score,
}))
}
That's the entire retrieval layer. No middleware, no pipeline stages, no "should I retrieve?" conditional logic in your application code. The LLM handles the decision-making. Your code just executes the search when asked.
The key detail is the tool description. That description is what teaches the model when to use the tool. Write it clearly, explain what kind of information the knowledge base contains, and the model will call it appropriately.
The Honest Tradeoffs
We're opinionated, but we're not going to pretend this approach has no downsides. It does.
Latency
In a traditional RAG pipeline, retrieval happens in parallel with (or before) the LLM call. With tool-based RAG, the LLM first needs to generate a tool call, then your system executes the search, then the LLM generates the final response. That's at minimum one extra round trip to the model. For latency-sensitive applications, this matters.
You can mitigate this with streaming (start showing the response as soon as the model begins generating after the tool call) and fast embedding/search infrastructure. But the extra LLM call is real overhead.
Model Capability Variance
Not all models are equally good at tool calling. GPT-4o and Claude are excellent — they reliably decide when to call tools and formulate good queries. Smaller or older models can be inconsistent. They might call the tool when they shouldn't, skip it when they should, or generate malformed tool calls. If you're using a less capable model, traditional RAG's simplicity has real value.
Cost
More LLM calls means more spend. Every time the model decides "I need to search for this," that decision itself costs tokens. For high-volume, low-margin use cases, the extra inference cost of the decision-making step might not be worth it.
Simplicity for Simple Use Cases
If you're building a Q&A bot over a single document set where every question requires retrieval — a product documentation bot, for example — traditional RAG is simpler and works fine. The "should I retrieve?" decision is always yes. The query reformulation benefit is marginal when questions are already specific. In this case, the traditional pipeline is the pragmatic choice.
When to Use Which
This isn't a "one approach for everything" situation. Here's a practical decision framework:
Use traditional RAG when:
- Every user query needs retrieval (single-purpose doc Q&A bot)
- You're using a model with weak tool-calling capabilities
- Latency is your top constraint and you can't afford the extra round trip
- The system has a single knowledge source with no other tools
Use RAG as a tool when:
- The assistant handles mixed queries (some need retrieval, some don't)
- You have multiple data sources or knowledge bases
- The assistant has other capabilities (API calls, database queries, calculations)
- You want iterative retrieval (search, evaluate, search again)
- You're building anything that resembles an agent
For most production systems we build, the answer is tool-based RAG. Real assistants don't just answer questions from a single document set. They check databases, call APIs, search different knowledge bases depending on the question, and sometimes don't need to search at all. The tool-based approach handles all of this naturally. Traditional RAG requires bolting on more and more conditional logic until you've essentially rebuilt tool calling yourself, poorly.
The Bigger Picture
RAG as a tool isn't just a technical optimization. It reflects a fundamental shift in how we should think about LLM architectures.
The traditional RAG pipeline treats the LLM as a text generator sitting at the end of a data pipeline. You do all the "thinking" in your application code — when to retrieve, what to retrieve, how to format it — and the LLM just generates prose from the assembled context.
Tool-based RAG treats the LLM as a reasoning engine that drives the entire interaction. It decides what information it needs, goes and gets it, evaluates the results, and takes further action if necessary. Your application code becomes infrastructure — executing searches, calling APIs, returning results — while the LLM orchestrates the workflow.
This is the direction the entire industry is heading. Agents, multi-step reasoning, tool use, planning. Traditional RAG was a necessary first step when models couldn't reliably call tools. Now they can. It's time to let them.
We build AI assistants and chatbots that use tool-based retrieval as a core architecture pattern. If you're designing a system that needs to search, reason, and act — not just retrieve and generate — take a look at our chatbot development services or reach out directly. We'll tell you which approach actually fits your use case.